-

关注微信
-

联系电话

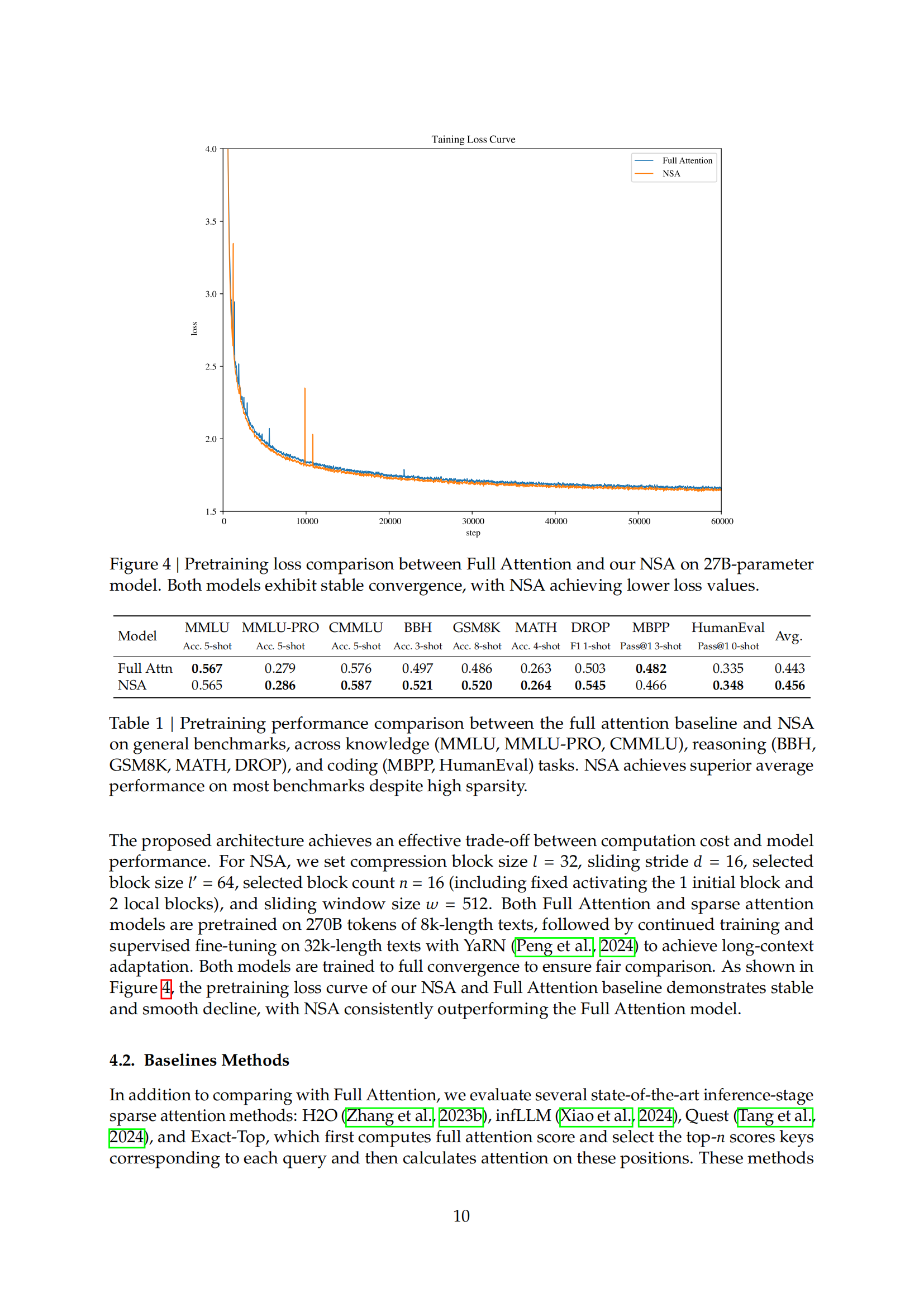
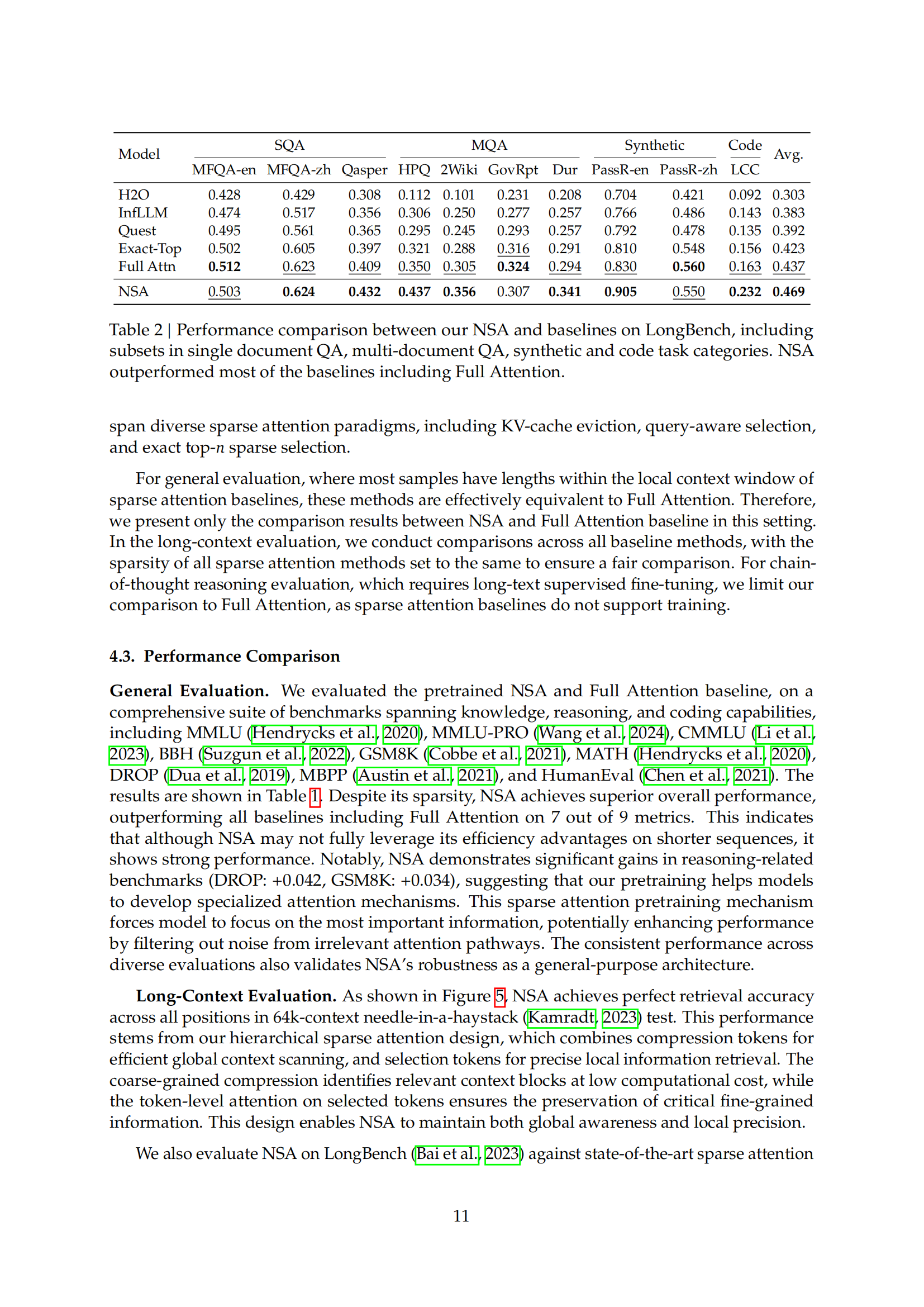
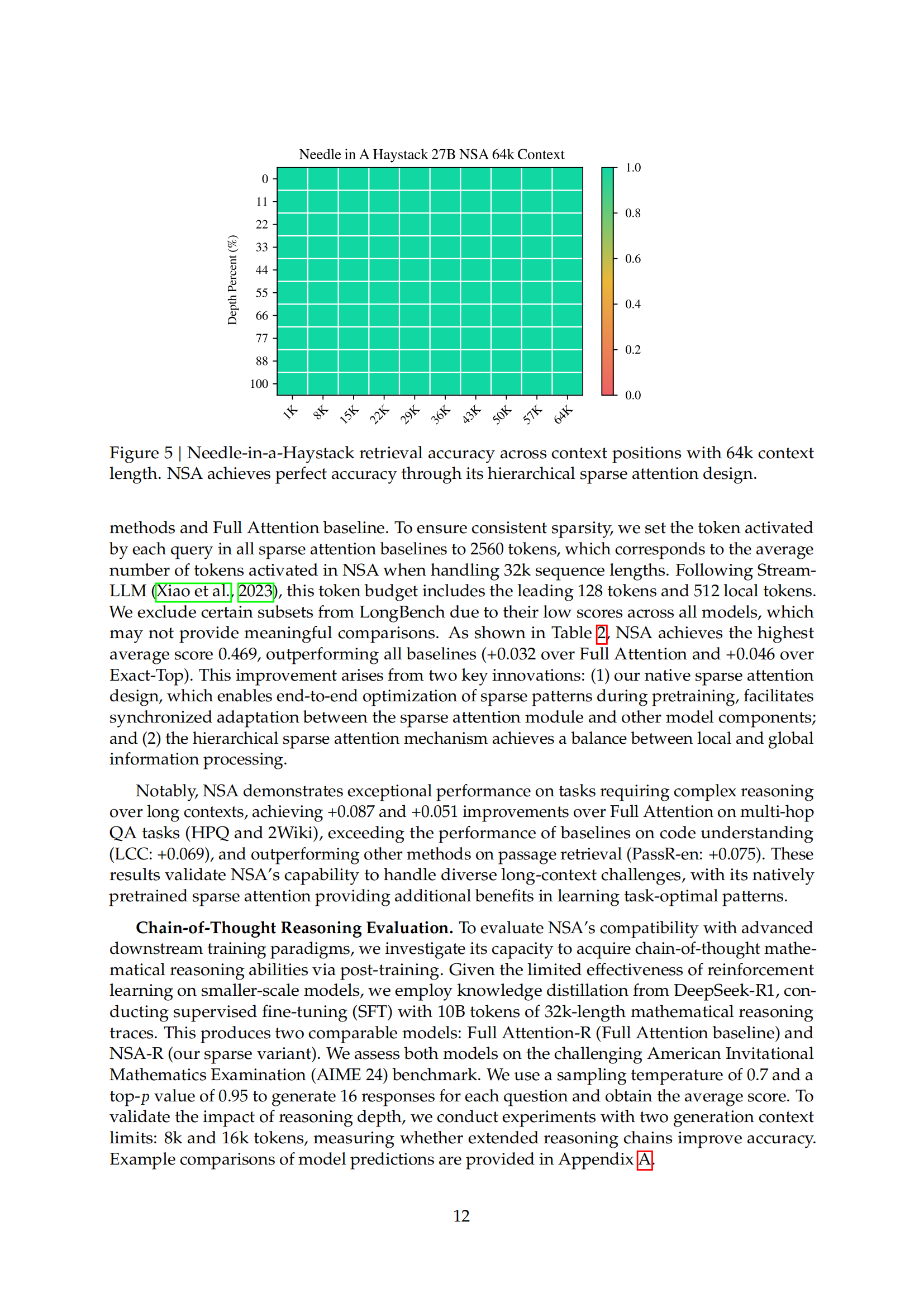
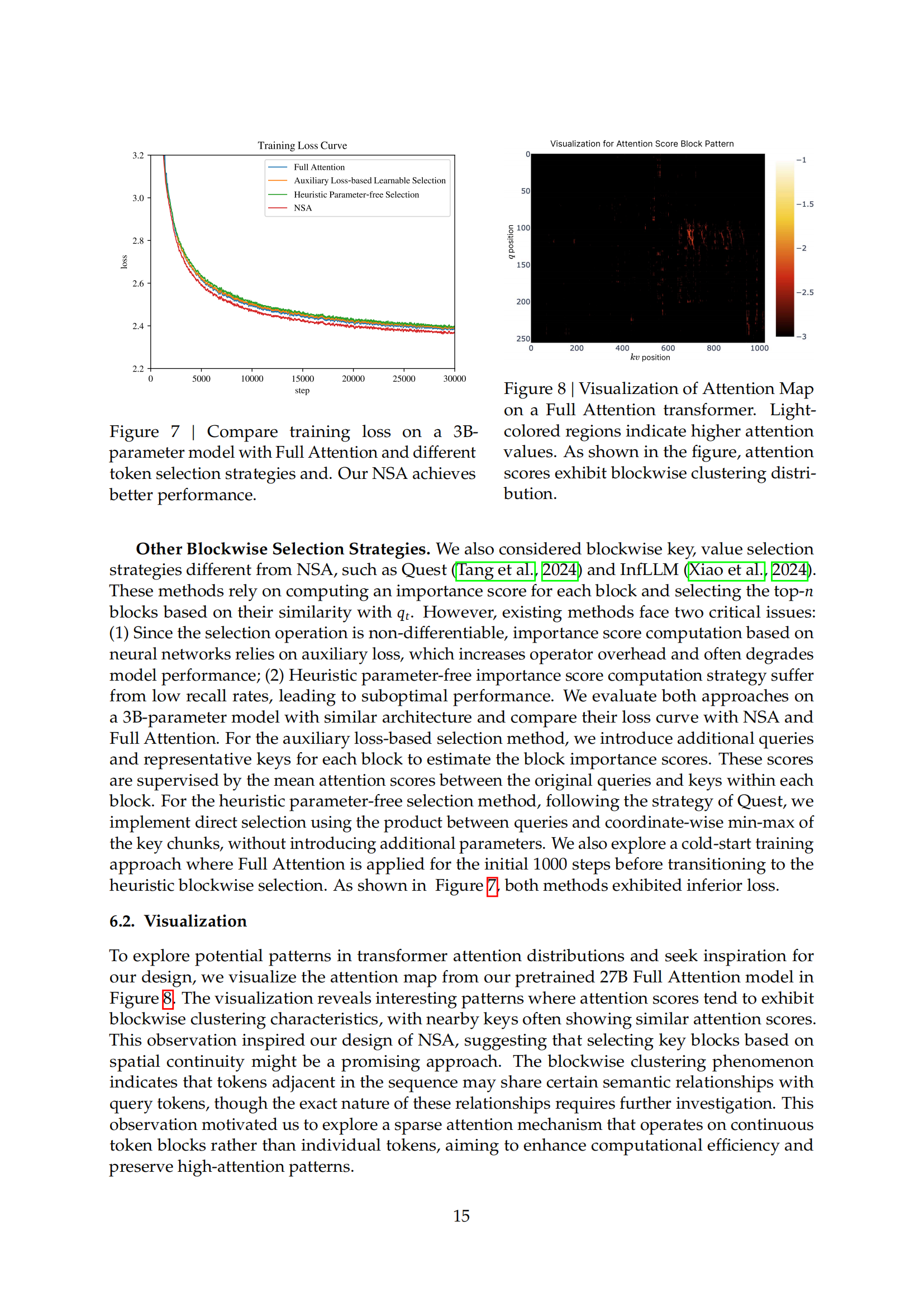
稀疏注意力(Sparse Attention)为提高效率的同时保持模型能力提供了一个有前景的方向。本文提出了NSA(原生可训练的稀疏注意力机制),通过算法创新与硬件优化相结合,实现高效的长上下文建模。NSA采用动态分层稀疏策略,将粗粒度的Token压缩与细粒度的Token选择相结合,既保留了全局上下文感知,又保证了局部精度。和易单招网小编一起学习AI!





















微信识别二维码 关注官方公众号

易单招
微信账号:danzhaobang 复制
易单招合作热线
15996434567
周一至周日:9:00-21:00
2013-2025 易单招,All Rights Reserved.|苏ICP备18060098号-16 |
 苏公网安备
50019002502480号
苏公网安备
50019002502480号
公司地址:南京市栖霞区栖霞街道广月路30-06号

报名咨询
官方微信



